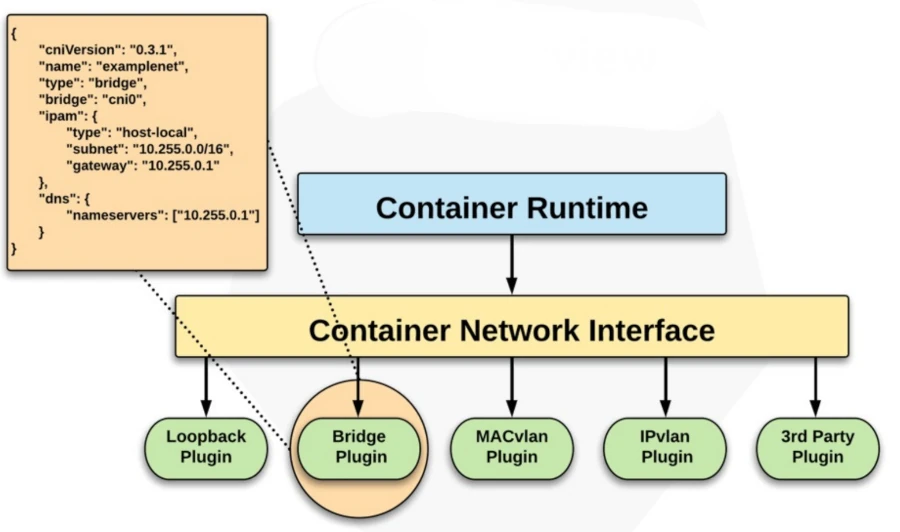
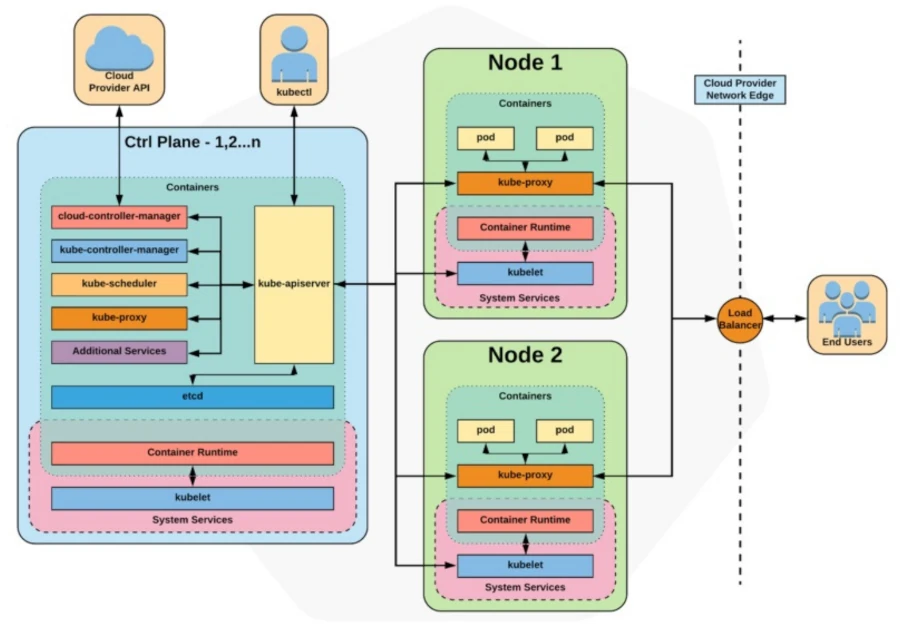
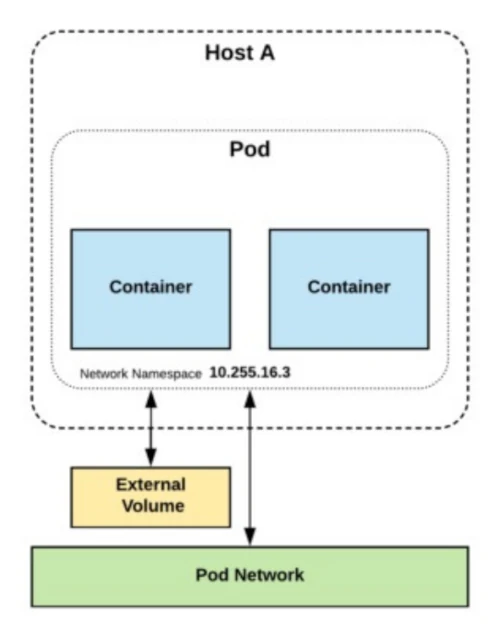
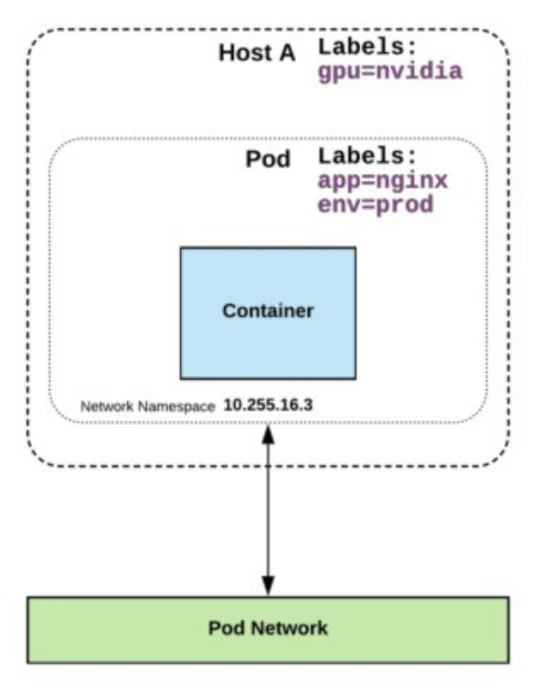
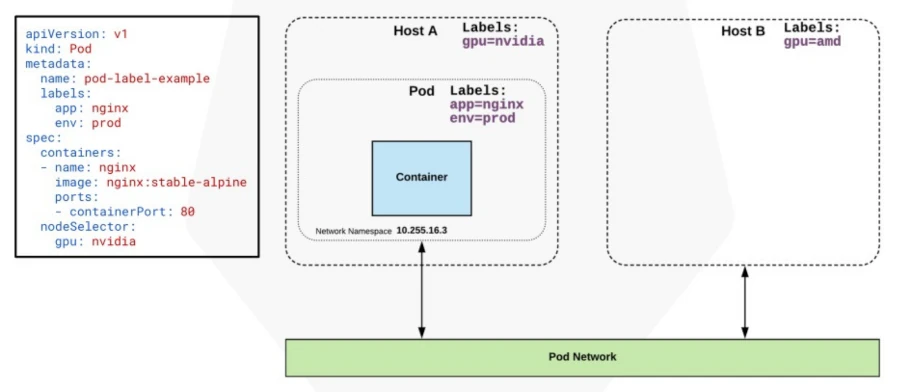
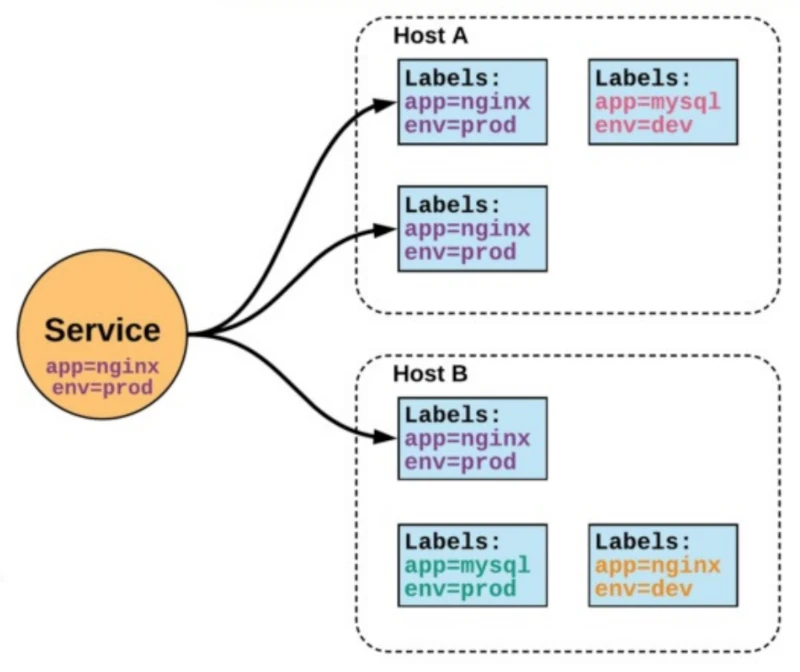
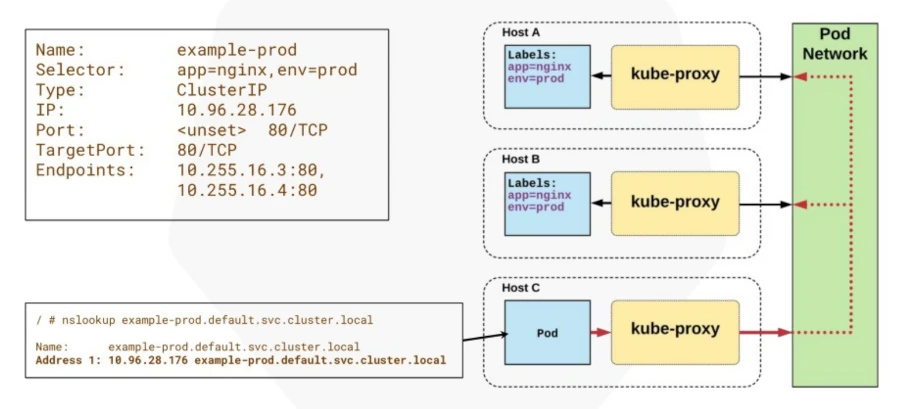
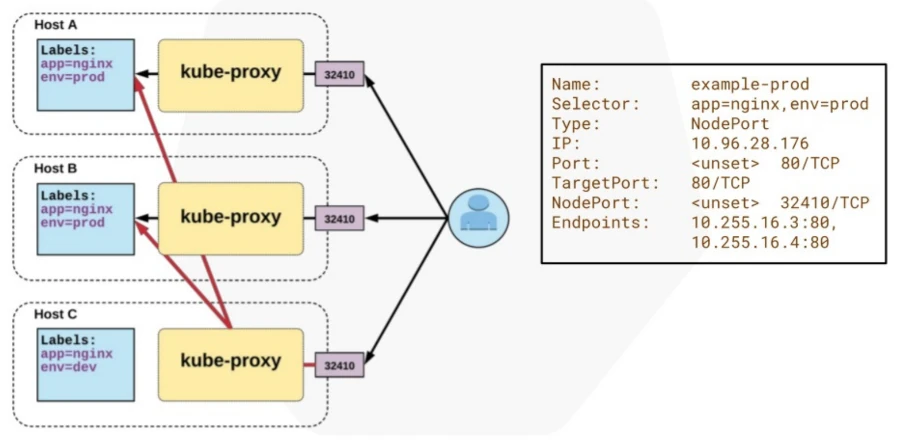
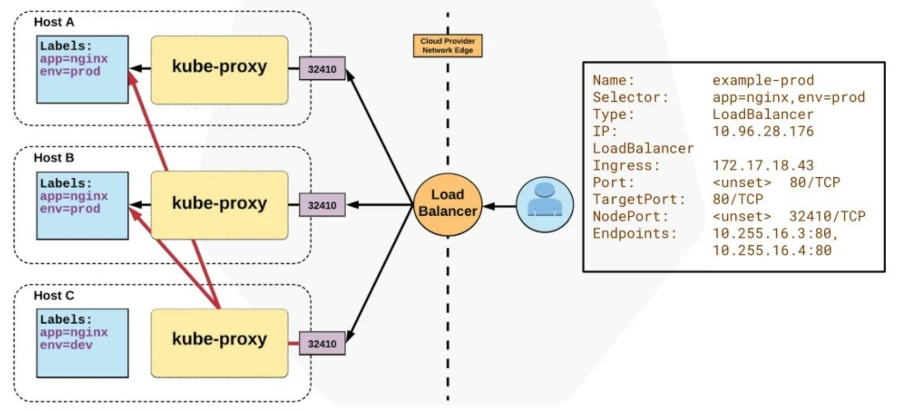
Cargas de Trabajo en Kubernetes
Kubernetes ofrece un conjunto de controladores de recursos conocidos como «cargas de trabajo» para administrar y supervisar la creación y el funcionamiento de los pods de manera eficiente. Estos controladores aseguran que los pods se implementen, escalen y administren de acuerdo con las necesidades de la aplicación y las políticas definidas.
ReplicaSet
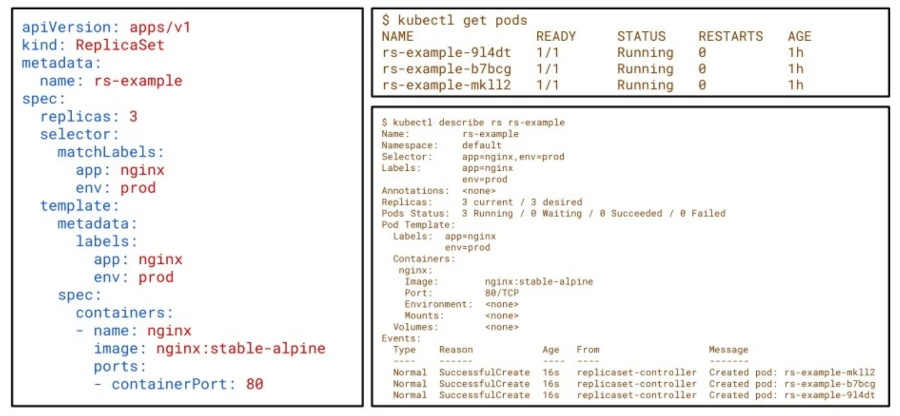
ReplicaSet es un controlador que garantiza que un número específico de réplicas de un pod esté en ejecución en todo momento. Si un pod falla o se elimina, ReplicaSet lo reemplazará automáticamente para mantener el número deseado de réplicas.
Uso típico: ReplicaSet es útil cuando se necesita garantizar la alta disponibilidad de una aplicación al mantener un número constante de copias idénticas en funcionamiento.
Deployment
Deployment es un controlador que abstrae ReplicaSets y proporciona un mecanismo más avanzado para administrar la implementación de aplicaciones. Permite realizar actualizaciones sin tiempo de inactividad al cambiar las versiones de las aplicaciones y garantiza que las actualizaciones se apliquen de manera controlada.
Uso típico: Los Deployments son ideales para administrar aplicaciones en constante evolución, como aplicaciones web, permitiendo actualizaciones y cambios sin interrupciones en el servicio.
DaemonSet
DaemonSet es un controlador que asegura que todos los nodos del clúster tengan una copia de un pod en ejecución. Cada nodo del clúster ejecuta una instancia del pod gestionado por DaemonSet.
Uso típico: DaemonSet es útil para implementar componentes que deben estar presentes en cada nodo, como agentes de monitoreo, recolección de registros o servicios de red.
StatefulSet
StatefulSet es un controlador diseñado para aplicaciones que requieren almacenamiento persistente y una identidad única y estable. Los pods administrados por StatefulSet tienen nombres y persisten su estado, lo que facilita la gestión de aplicaciones que requieren un estado específico, como bases de datos.
Uso típico: StatefulSet es esencial para aplicaciones de bases de datos, sistemas de mensajería y otras aplicaciones que necesitan nombres únicos y almacenamiento persistente.
Job
Job es un controlador que garantiza que uno o más pods se ejecuten y finalicen con éxito. Los pods administrados por Job realizan una tarea y no se eliminan hasta que se completa la tarea con éxito o se alcanza un límite de reintentos.
Uso típico: Los Jobs son adecuados para tareas de procesamiento por lotes, trabajos de cómputo intensivo y cualquier trabajo que deba completarse antes de ser eliminado.
CronJob
CronJob es una extensión del controlador de trabajos (Job) que permite ejecutar trabajos de manera programada, similar a la funcionalidad de cron en sistemas operativos. Los CronJobs ejecutan trabajos en un horario específico o periódicamente.
Uso típico: CronJobs son útiles para automatizar tareas recurrentes, como copias de seguridad, generación de informes o limpieza de registros, siguiendo un horario predefinido.