
¿Te preguntas qué hacen esas extrañas cadenas de símbolos en Linux? ¡Pues es magia en la línea de comandos! En este artículo vamos a lanzar hechizos con expresiones regulares (regex).
Además de Linux, las expresiones regulares se utilizan en una amplia variedad de contextos y plataformas en el campo de la informática y la programación. Algunos ejemplos de dónde más se usan son:
- Programación en General: Son una herramienta común en muchos lenguajes de programación, como Python, JavaScript, Java, etc.
- Editores de Texto y IDEs: Muchos editores de texto y entornos de desarrollo integrados (IDEs) ofrecen soporte para expresiones regulares.
- Bases de Datos: Algunas bases de datos y sistemas de gestión de bases de datos (DBMS) permiten el uso de expresiones regulares en consultas y búsquedas.
- Validación de Entrada de Usuario: Las regex son valiosas para validar la entrada del usuario en formularios y aplicaciones.
- Web Scraping: Cuando necesitas extraer información de sitios web, las expresiones regulares son unas grandes aliadas para buscar y capturar patrones específicos de datos en el contenido HTML.
- Análisis de Log: En el análisis de registros y archivos de registro, las regex son esenciales para buscar patrones específicos y extraer información relevante.
- Automatización de Tareas: Las expresiones regulares son útiles en scripts y programas que automatizan tareas, como la reorganización de archivos, el formateo de datos y más.
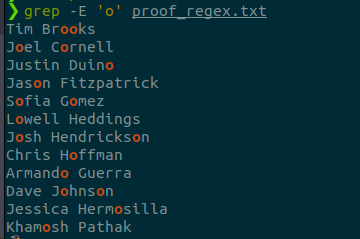
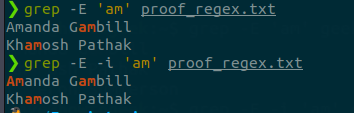
Y podrás utilizarlas en muchos sitios más, por ejemplo, ya lo vimos en la «guía del comando sed». Aquí nos vamos a centrar a usarlas con el comando grep en una terminal linux. Para ver más sobre comandos de búsqueda en Linux: «grep, find y locate. Comandos de búsqueda en Linux»