

Puede parecer una locura, pero el comando sed de Linux es un editor de texto sin interfaz. Se puede utilizar desde la línea de comandos para manipular texto en archivos y secuencias. Te mostraré algunas formas de aprovechar su poder.
Guía del comando sed

El comando sed es un poco como el ajedrez: se tarda una hora en aprender los conceptos básicos y toda una vida en dominarlos (o, al menos, mucha práctica). Vamos a ver una selección de estrategias de uso en cada una de las principales categorías de funcionalidad de sed.
sed es un editor de flujos que trabaja con entradas o archivos de texto. Sin embargo, no tiene una interfaz de editor de texto interactivo. Más bien, le proporcionas instrucciones para que las siga a medida que trabaja a través del texto. Todo esto funciona en Bash y otros shells de línea de comandos.
Con sed puedes hacer todo lo siguiente:
- Seleccionar texto
- Sustituir texto
- Añadir líneas al texto
- Eliminar líneas del texto
- Modificar (o conservar) un archivo original
Se ha estructurado ejemplos para introducir y demostrar conceptos, no para producir los comandos sed más complejos (y menos accesibles). Sin embargo, las funcionalidades de coincidencia de patrones y selección de texto de sed se basan en gran medida en expresiones regulares (regexes). Necesitarás familiarizarte con ellas para sacar el máximo partido a sed.
Un ejemplo sencillo
En primer lugar, vamos a utilizar echo para enviar algo de texto a sed a través de una tubería, y hacer que sed sustituya una parte del texto. Para ello, escribiremos lo siguiente
echo vergaracarmona.es | sed 's/es/com/'
El comando echo envía «vergaracarmona.es» con la tubería a sed, y se aplica la regla de sustitución simple (la «s» significa sustitución). sed busca en el texto de entrada una ocurrencia de la primera cadena, y sustituirá cualquier coincidencia por la segunda.
La cadena «es» se sustituye por «com», y la nueva cadena se imprime en la ventana del terminal:
vergaracarmona.com
Las sustituciones son probablemente el uso más común de sed. Sin embargo, antes de que podamos profundizar en las sustituciones, necesitamos saber cómo seleccionar y emparejar texto.
Seleccionar texto
Vamos a necesitar un archivo de texto para nuestros ejemplos. Usaremos uno que contenga los primeros versos del poema épico de José de Espronceda «La canción del pirata».
Escribimos lo siguiente para echarle un vistazo al fichero con less:
less pirata.txt
Con diez cañones por banda, viento en popa, a toda vela, no corta el mar, sino vuela, un velero bergantín. Bajel pirata que llaman, por su bravura, El Temido, en todo mar conocido, del uno al otro confín. La luna en el mar riela, en la lona gime el viento, y alza en blando movimiento olas de plata y azul; y ve el capitán pirata, cantando alegre en la popa, Asia a un lado, al otro Europa, y allá a su frente Estambul: «Navega, velero mío, sin temor, que ni enemigo navío ni tormenta, ni bonanza tu rumbo a torcer alcanza, ni a sujetar tu valor. Veinte presas hemos hecho a despecho del inglés, y han rendido sus pendones cien naciones a mis pies.»
Para seleccionar algunas líneas del archivo, proporcionamos las líneas inicial y final del rango que queremos seleccionar. Un solo número selecciona esa única línea.
Para extraer las líneas uno a cuatro, escribimos este comando:
sed -n '1,4p' pirata.txt
El resultado:
Con diez cañones por banda, viento en popa, a toda vela, no corta el mar, sino vuela, un velero bergantín.
Fíjate en la coma entre 1 y 4. La p significa «imprimir las líneas coincidentes». Por defecto, sed imprime todas las líneas. Veríamos todo el texto del archivo con las líneas coincidentes impresas dos veces. Para evitarlo, utilizaremos la opción -n (quiet) para suprimir el texto no coincidente.
Cambiamos los números de línea para poder seleccionar un verso diferente, como se muestra a continuación:
sed -n '5,9p' pirata.txt
Con el resultado:
Bajel pirata que llaman, por su bravura, El Temido, en todo mar conocido, del uno al otro confín.
Podemos utilizar la opción -e (expresión) para realizar selecciones múltiples. Con dos expresiones, podemos seleccionar dos versículos, como se indica a continuación:
sed -n -e '1,4p' -e '26,34p' pirata.txt
Si reducimos el primer número de la segunda expresión, podemos insertar el espacio en blanco entre los dos versos. Escribimos lo siguiente:
sed -n -e '1,4p' -e '25,34p' pirata.txt
El resultado del segundo comando es:
Con diez cañones por banda, viento en popa, a toda vela, no corta el mar, sino vuela, un velero bergantín. Veinte presas hemos hecho a despecho del inglés, y han rendido sus pendones cien naciones a mis pies.»
También podemos elegir una línea de inicio y decirle a sed que recorra el archivo e imprima líneas alternas, cada cinco líneas, o que se salte cualquier número de líneas. Utilizaremos una tilde (~) en lugar de una coma para separar los números.
El primer número indica la línea inicial. El segundo número indica a Sed qué líneas después de la línea inicial queremos ver. El número 2 significa cada segunda línea, el 3 significa cada tercera línea, y así sucesivamente.
Escribimos lo siguiente
sed -n '1~3p' pirata.txt
Y tendremos un poemos conceptual nuevo:
Con diez cañones por banda, Bajel pirata que llaman, olas de plata y azul; y allá a su frente Estambul: que ni enemigo navío del inglés, a mis pies.»
No siempre sabrás en qué parte del archivo se encuentra el texto que buscas, lo que significa que los números de línea no siempre serán de mucha ayuda. Sin embargo, también puede utilizar sed para seleccionar líneas que contengan patrones de texto coincidentes. Por ejemplo, extraigamos todas las líneas que empiecen por «ni».
El signo de intercalación (^) representa el inicio de la línea. Encerraremos el término de búsqueda entre barras inclinadas (/). También incluiremos un espacio después de «ni» para que palabras como «ningún» no se incluyan en el resultado.
Leer scripts sed puede ser un poco difícil al principio. La /p significa «imprimir», igual que en los comandos que hemos utilizado anteriormente. En el siguiente comando, sin embargo, le precede una barra oblicua:
sed -n '/^ni /p' pirata.txt
Se extraen del archivo dos líneas que empiezan por «ni » y se muestran.
ni tormenta, ni bonanza ni a sujetar tu valor.
Cómo hacer sustituciones
En el primer ejemplo, vimos el siguiente formato básico para una sustitución sed:
echo vergaracarmona.es | sed 's/es/com/'
La s indica a sed que se trata de una sustitución. La primera cadena es el patrón de búsqueda, y la segunda es el texto con el que queremos reemplazar ese texto coincidente. Por supuesto, como con todas las cosas de Linux, el diablo está en los detalles.
Escribimos lo siguiente para cambiar todas las apariciones de «pirata» a «señor» para darle un respeto al marinero:
sed -n 's/pirata/señor/p' pirata.txt
Si editamos el archivo y en una línea donde salga «pirata» ponemos un segundo pirata y ejecutamos de nuevo el comando, veremos que con ese comando sólo cambia la primera aparición de «pirata»:
Bajel señor que llaman, pirata, y ve el capitán señor,
Esto se debe a que sed se detiene tras la primera coincidencia por línea. Tenemos que añadir una «g» al final de la expresión, como se muestra a continuación, para realizar una búsqueda global de forma que se procesen todas las coincidencias de cada línea:
sed -n 's/pirata/señor/gp' pirata.txt
Nos devuelve esto:
Bajel señor que llaman, señor, y ve el capitán señor,
Ahora, si añadimos un tercer «Pirata» pero con la p mayúscula, necesitaremos la opción i al comando para indicar que no distinga entre mayúsculas y minúsculas:
sed -n 's/pirata/señor/gip' pirata.txt
señor. Bajel señor que llaman, señor, y ve el capitán señor,
Esto funciona, pero es posible que no siempre desee activar la insensibilidad a mayúsculas y minúsculas para todo. En esos casos, puede utilizar un grupo regex para añadir la insensibilidad a mayúsculas y minúsculas a un patrón específico. Por ejemplo, si encerramos caracteres entre corchetes ([]), se interpretan como «cualquier carácter de esta lista de caracteres».
Escribimos lo siguiente, e incluimos «P» y «p» en el grupo, para asegurarnos de que coincide tanto con «Pirata» como con «pirata»:
sed -n 's/[Pp]irata/señor/gp' pirata.txt
También podemos restringir las sustituciones a secciones del archivo. Supongamos que nuestro archivo contiene un espaciado extraño en el primer verso. Podemos utilizar el siguiente comando conocido para ver el primer verso:
sed -n '1,4p' pirata.txt
Buscaremos dos espacios y los sustituiremos por uno. Lo haremos de forma global para que la acción se repita en toda la línea. Para que quede claro, el patrón de búsqueda es espacio, espacio asterisco (*), y la cadena de sustitución es un solo espacio. El 1,4 restringe la sustitución a las cuatro primeras líneas del fichero.
Juntamos todo eso en el siguiente comando:
sed -n '1,4 s/ */ /gp' pirata.txt
Funciona a la perfección. Lo importante aquí es el patrón de búsqueda. El asterisco (*) representa cero o más del carácter precedente, que es un espacio. Por lo tanto, el patrón de búsqueda busca cadenas de un espacio o más.
Si sustituimos cualquier secuencia de espacios múltiples por un único espacio, devolveremos al fichero el espaciado normal, con un único espacio entre cada palabra. Esto también sustituirá un único espacio por un único espacio en algunos casos, pero no afectará negativamente a nada: seguiremos obteniendo el resultado deseado.
Si escribimos lo siguiente y reducimos el patrón de búsqueda a un solo espacio, verá inmediatamente por qué tenemos que incluir dos espacios:
sed -n '1,4 s/ */ /gp' pirata.txt
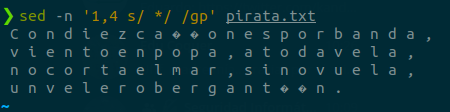
Como el asterisco coincide con cero o más del carácter precedente, considera cada carácter que no es un espacio como un «espacio cero» y le aplica la sustitución.
Sin embargo, si incluimos dos espacios en el patrón de búsqueda, sed debe encontrar al menos un carácter de espacio antes de aplicar la sustitución. De este modo se garantiza que los caracteres no espaciados permanezcan intactos.
Escribimos lo siguiente, utilizando la -e (expresión) que usamos antes, que nos permite hacer dos o más sustituciones simultáneamente:
sed -n -e 's/cañones/piruletas/gip' -e 's/Estambul/Móstoles/gip' pirata.txt
Podemos obtener el mismo resultado si utilizamos un punto y coma (;) para separar las dos expresiones, de esta forma
sed -n 's/cañones/piruletas/gip;s/Estambul/Móstoles/gip' pirata.txt
Cuando cambiamos «pirata» por «señor» en el siguiente comando, también se cambió la instancia de «día» que añadimos:
sed -n 's/[Pp]irata/señor/gp' pirata.txt
Para evitarlo, sólo podemos intentar sustituciones en líneas que coincidan con otro patrón. Si modificamos el comando para que tenga un patrón de búsqueda al principio, sólo consideraremos operar sobre las líneas que coincidan con ese patrón.
Escribimos lo siguiente para que nuestro patrón de búsqueda sea la palabra «Bajel»:
sed -n '/Bajel/ s/[Pp]irata/señor/gp' pirata.txt
Esto nos da la respuesta que queremos.
Sustituciones más complejas
Demos un descanso al Pirata y utilicemos sed para extraer nombres del fichero etc/passwd. Hay formas más cortas de hacerlo (más adelante hablaremos de ello), pero primero vamos a ver la más larga para demostrar otro concepto. Cada elemento coincidente en un patrón de búsqueda (llamado subexpresiones) puede numerarse (hasta un máximo de nueve elementos). Puede utilizar estos números en sus órdenes sed para hacer referencia a subexpresiones específicas.
Para que esto funcione, debe encerrar la subexpresión entre paréntesis [()]. Los paréntesis también deben ir precedidos de una barra oblicua (\) para evitar que sean tratados como un carácter normal. Para ello, usamos el siguiente comando:
sed 's/\([^:]*\).*/\1/' /etc/passwd
Vamos a desglosarlo:
sed ‘s/: El comando sed y el comienzo de la expresión de sustitución.
\(: El paréntesis de apertura [(] que encierra la subexpresión, precedido por una barra invertida (\).
[^:]*: La primera subexpresión del término de búsqueda contiene un grupo entre corchetes. El signo de intercalación (^) significa «no» cuando se utiliza en un grupo. Un grupo significa que cualquier carácter que no sea dos puntos (:) se aceptará como coincidencia.
\): El paréntesis de cierre [)] con una barra invertida precedente (\).
.*: Esta segunda subexpresión de búsqueda significa «cualquier carácter y cualquier número de ellos».
/\1: La parte de sustitución de la expresión contiene 1 precedido de una barra invertida (\). Representa el texto que coincide con la primera subexpresión.
/’: La barra diagonal de cierre (/) y la comilla simple (‘) terminan el comando sed.
Lo que significa todo esto es que vamos a buscar cualquier cadena de caracteres que no contenga dos puntos (:), que será la primera instancia de texto coincidente. Luego, buscaremos cualquier otra cosa en esa línea, que será la segunda instancia de texto coincidente. Vamos a sustituir toda la línea por el texto que coincida con la primera subexpresión.
Cada línea del archivo /etc/passwd comienza con un nombre de usuario terminado en dos puntos. Hacemos coincidir todo hasta los primeros dos puntos, y luego sustituimos ese valor para toda la línea. Así, hemos aislado los nombres de usuario.
A continuación, encerraremos la segunda subexpresión entre paréntesis [()] para poder referenciarla también por número. También sustituiremos \1 por \2. Nuestro comando sustituirá ahora toda la línea desde los primeros dos puntos (:) hasta el final de la línea.
Escribimos lo siguiente
sed 's/\([^:]*\)\(.*\)/\2/' /etc/passwd
Esos pequeños cambios invierten el significado del comando, y obtenemos todo excepto los nombres de usuario.
Ahora, echemos un vistazo a la forma rápida y fácil de hacer esto.
Nuestro término de búsqueda va desde los primeros dos puntos (:) hasta el final de la línea. Como nuestra expresión de sustitución está vacía (//), no sustituiremos el texto coincidente por nada.
Por lo tanto, escribimos lo siguiente, cortando todo desde los primeros dos puntos (:) hasta el final de la línea, dejando sólo los nombres de usuario:
sed 's/:.*//' /etc/passwd
Veamos un ejemplo en el que hacemos referencia a la primera y segunda coincidencias en el mismo comando.
Tenemos un archivo de comas (,) separando nombres y apellidos. Queremos listarlos como «apellido, nombre». Podemos usar cat, como se muestra a continuación, para ver lo que hay en el archivo:
cat frikis.txt
Como muchos comandos sed, el siguiente puede parecer impenetrable al principio:
sed 's/\([^:]*\)\(.*\)/\2/' /etc/passwd
Se trata de un comando de sustitución como los demás que hemos utilizado, y el patrón de búsqueda es bastante sencillo. Lo desglosaremos a continuación:
sed ‘s/: El comando de sustitución normal.
^: Como el signo de intercalación no está en un grupo ([]), significa «El comienzo de la línea».
\(.*\),: La primera subexpresión es un número cualquiera de caracteres. Está encerrada entre paréntesis [()], cada uno de los cuales va precedido de una barra invertida (\) para que podamos referenciarla por número. Nuestro patrón de búsqueda completo hasta ahora se traduce como búsqueda desde el inicio de la línea hasta la primera coma (,) de cualquier número de caracteres cualesquiera.
\(.*\): La siguiente subexpresión es (de nuevo) cualquier número de cualquier carácter. También está encerrada entre paréntesis [()], ambos precedidos por una barra invertida (\) para que podamos referenciar el texto coincidente por número.
$/: El signo del dólar ($) representa el final de la línea y permitirá que nuestra búsqueda continúe hasta el final de la línea. Lo hemos utilizado simplemente para introducir el signo del dólar. Realmente no lo necesitamos aquí, ya que el asterisco (*) iría al final de la línea en este escenario. La barra oblicua (/) completa la sección del patrón de búsqueda.
\2,\1 /g’: Como hemos encerrado nuestras dos subexpresiones entre paréntesis, podemos referirnos a ambas por sus números. Como queremos invertir el orden, las escribimos como segunda-partida,primera-partida. Los números deben ir precedidos de una barra invertida (\).
/g: Esto permite que nuestro comando funcione globalmente en cada línea.
frikis.txt: El archivo en el que estamos trabajando.
También puedes utilizar el comando Cortar (c) para sustituir líneas enteras que coincidan con tu patrón de búsqueda. Escribimos lo siguiente para buscar una línea que contenga la palabra «cuello» y sustituirla por una nueva cadena de texto:
sed '/cañones/c Con nuestro barquito de papel' pirata.txt
Nuestra nueva línea le da un nuevo toque al inicio del poema:
Con nuestro barquito de papel viento en popa, a toda vela, no corta el mar, sino vuela, un velero bergantín. Pirata. Bajel pirata que llaman, pirata, por su bravura, El Temido, en todo mar conocido, del uno al otro confín. La luna en el mar riela, en la lona gime el viento, y alza en blando movimiento olas de plata y azul; y ve el capitán pirata, cantando alegre en la popa, Asia a un lado, al otro Europa, y allá a su frente Estambul: «Navega, velero mío, sin temor, que ni enemigo navío ni tormenta, ni bonanza tu rumbo a torcer alcanza, ni a sujetar tu valor. Veinte presas hemos hecho a despecho del inglés, y han rendido sus pendones cien naciones a mis pies.»
Insertar líneas y texto
También podemos insertar nuevas líneas y texto en nuestro fichero. Para insertar nuevas líneas después de las que coincidan, utilizaremos el comando Append (a). Este es el archivo con el que vamos a trabajar:
cat frikis.txt
1 Manuel,Vergara 2 Marta,Sanchez 3 Anton,Husein 4 José,Olivar 5 Clara,García 6 Mohamed,Gonzalez 7 John,Estebez
Se ha numerado las líneas para que sea un poco más fácil de seguir.
Escribimos lo siguiente para buscar las líneas que contengan la palabra «Hu», e insertamos una nueva línea debajo de ellas:
sed '/Hu/a --> ¡Insertado!' frikis.txt
Escribimos lo siguiente e incluimos el comando Insertar (i) para insertar la nueva línea por encima de las que contienen texto coincidente:
sed '/Hu/i --> ¡Insertada!' geeks.txt
Podemos utilizar el ampersand (&), que representa el texto coincidente original, para añadir nuevo texto a una línea coincidente. \1 , \2, etc., representan subexpresiones coincidentes.
Para añadir texto al principio de una línea, utilizaremos un comando de sustitución que coincide con todo lo que hay en la línea, combinado con una cláusula de sustitución que combina nuestro nuevo texto con la línea original.
Para hacer todo esto, escribimos lo siguiente:
sed 's/.*/--> Insertado &/' frikis.txt
Escribimos lo siguiente, incluyendo el comando G, que añadirá una línea en blanco entre cada línea:
sed 'G' geeks.txt
Si quieres añadir dos o más líneas en blanco, puedes utilizar G;G, G;G;G, etc.
Borrado de líneas
El comando Delete (d) borra las líneas que coinciden con un patrón de búsqueda, o las especificadas con números de línea o rangos.
Por ejemplo, para borrar la tercera línea, escribiríamos lo siguiente:
sed '3d' frikis.txt
Para borrar el rango de líneas cuatro a cinco, escribiríamos lo siguiente
sed '4,5d' frikis.txt
Para borrar líneas fuera de un rango, utilizamos un signo de exclamación (!), como se muestra a continuación:
sed '6,7!d' frikis.txt
Guardar los cambios
Hasta ahora, todos nuestros resultados se han impreso en la ventana del terminal, pero aún no los hemos guardado en ningún sitio. Para hacerlos permanentes, puedes escribir los cambios en el archivo original o redirigirlos a uno nuevo.
Sobrescribir el archivo original requiere cierta precaución. Si el comando sed es erróneo, podría hacer cambios en el archivo original que son difíciles de deshacer. Para mayor tranquilidad, sed puede crear una copia de seguridad del archivo original antes de ejecutar su comando.
Puede utilizar la opción In-place (-i) para indicar a sed que escriba los cambios en el archivo original, pero si le añade una extensión de archivo, sed hará una copia de seguridad del archivo original en uno nuevo. Tendrá el mismo nombre que el archivo original, pero con una nueva extensión de archivo.
Para demostrarlo, buscaremos todas las líneas que contengan la palabra «Ma» y las borraremos. También haremos una copia de seguridad de nuestro archivo original en uno nuevo utilizando la extensión BAK.
Para hacer todo esto, escribimos lo siguiente:
sed -i'.bak' '/^.*Ma.*$/d' frikis.txt
Cuidado, si lo ejecutas dos veces se pisará el archivo y quedarán los dos iguales. Escribimos lo siguiente para asegurarnos de que nuestro archivo de copia de seguridad no se ha modificado:
cat frikis.txt.bak
También podemos escribir lo siguiente para redirigir la salida a un nuevo archivo y obtener un resultado similar:
sed -i'.bak' '/^.*Ma.*$/d' frikis.txt > nuevos_frikis.txt
Utilizamos cat para confirmar que los cambios se han escrito en el nuevo archivo, como se muestra a continuación:
cat nuevos_frikis.txt
Conclusión
Como probablemente hayas notado, incluso este rápido manual sobre sed es bastante largo. Hay mucho en este comando, y hay aún más que puede hacer con él.
Algunos enlaces que pueden resultar interesantes:
Más apuntes











También puedes invitarme a algo para mojar...
