Buenas prácticas con logs para una observabilidad integral del stack
Generar logs de todo el stack puede resultar abrumador. Los desarrolladores e ingenieros suelen enfrentarse a preguntas sobre qué incluir en los logs, cuánto detalle agregar y si el exceso de datos impactará negativamente en los costos. Con buenas prácticas para los registros se pueden evitar problemas a la hora de centralizar la observabilidad.
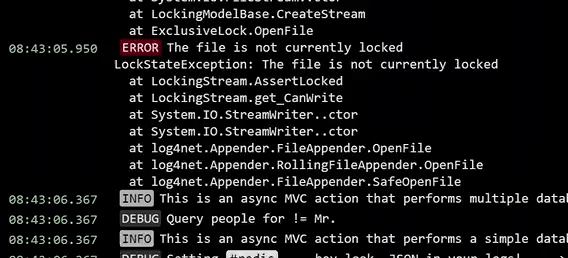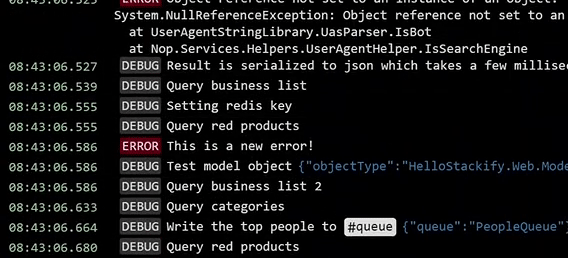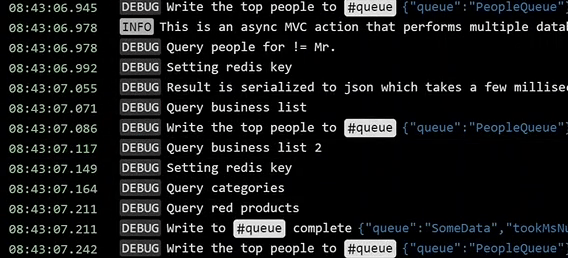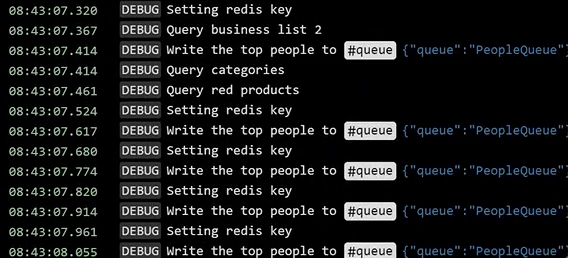
Los logs se generan mediante la escritura de texto en una salida estándar o un archivo. Es esencial seleccionar cuidadosamente qué información incluir en ellos. Los logs deben contener todos los metadatos necesarios para ayudar a identificar eventos y causas raíz durante investigaciones posteriores. Estos metadatos pueden abarcar mensajes de error, trazas de stack, valores métricos y eventos relacionados.
Todo lo que se incluya en los logs debe tener un propósito claro y proporcionar información valiosa para el equipo. La información en los datos de los logs debe:
- Ser útil de inmediato para localizar el contexto.
- Proporcionar los detalles necesarios para comprender las causas subyacentes y poder tomar decisiones.
Anticipar escenarios frecuentes
Los logs no solo deben utilizarse para responder a incidentes, sino que también pueden ser valiosos en otras áreas del negocio, como la creación de perfiles de rendimiento o la recopilación de datos estadísticos. Al anticipar escenarios comunes, se puede garantizar que los logs aporten un valor directo a la organización.
Por ejemplo, los logs relacionados con la interacción del usuario pueden ofrecer información crucial sobre la experiencia del cliente, mientras que los logs del sistema pueden monitorear problemas o fallos de hardware. Además, los logs que detallan el comportamiento de la aplicación pueden iluminar aspectos relacionados con el rendimiento y posibles problemas, como las fugas de memoria.
Incluir mensajes útiles en los logs
Los mensajes en los logs son valiosos solo si ofrecen la información y el contexto necesarios. Cuando los detalles son suficientes y los logs son comprensibles, los equipos pueden utilizarlos con eficacia. Si bien la infraestructura de terceros suele capturar los detalles granulares necesarios, para las aplicaciones internas, los equipos deben capturar detalles en los logs que permitan diagnosticar y determinar por qué ocurrió un error o evento.
Los mensajes de error deben proporcionar información sobre lo que está sucediendo, preferiblemente con detalles específicos, como la línea de código relevante. Los códigos de error o estados también deben ir acompañados de una breve descripción para facilitar la resolución de problemas.
Mantener los logs sencillos y concisos
Es importante encontrar un equilibrio entre la cantidad de información incluida en los logs y su concisión. Los datos innecesarios y excesivos pueden aumentar el tamaño del almacenamiento de los logs y los costos asociados, así como ralentizar las búsquedas y distraer del problema principal.
Los equipos deben mantener los logs concisos para capturar solo la información más crítica. Deben explicar por qué ocurrió un error y, al mismo tiempo, evitar excesos. Deben proporcionar información sobre la causa raíz sin incluir detalles irrelevantes del entorno.
No olvidar la fecha y hora
Incluir un timestamp en los logs es fundamental para contextualizar los eventos en el tiempo. Aunque pueda parecer obvio, algunos desarrolladores e ingenieros podrían pasar por alto este detalle, especialmente si están acostumbrados a sistemas que automáticamente registran la fecha y la hora en una base de datos.
Es recomendable seleccionar el nivel de granularidad apropiado para los logs. Las tareas frecuentes pueden requerir timestamps que incluyan hasta los milisegundos, mientras que para las tareas menos frecuentes, minutos o incluso solo el día pueden ser suficientes.
Además, es esencial que todos los sistemas estén sincronizados en el tiempo para permitir que una plataforma de observabilidad correlacione los eventos de los registros con otros datos de telemetría.
Ejemplos:
- Formato completo con milisegundos:
- 2024-05-08 12:30:45.678
- 2023-11-15 23:45:59.123
- Formato sin milisegundos:
- 2022-09-30 08:15:30
- 2024-03-17 18:20:00
- Formato con zona horaria:
- 2024-07-20 10:00:00.456 UTC
- 2023-12-10 15:30:20.789 EST
Estos ejemplos muestran diferentes formatos de timestamps que pueden utilizarse en los logs para proporcionar contexto temporal a los eventos registrados.
Es crucial que los registros sean analizables para extraer información significativa. Los equipos deben utilizar un formato de logs que los desarrolladores e ingenieros puedan procesar fácilmente y mantener una estructura uniforme para facilitar su recopilación y agregación.
Un ejemplo de un formato de logs no analizable es el registro de acceso predeterminado de NGINX, que consiste en texto sin estructura. Aunque es útil para realizar búsquedas, carece de la estructura necesaria para responder la mayoría de las preguntas.
Aquí tienes un ejemplo de una línea típica de registro de acceso de NGINX:
126.10.51.30 - - [2/May/2024:11:03:23 +0000] "GET /downloads/product_1 HTTP/1.1" 304 0 "-" "Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.21)"
Después de analizarlo, el registro se organiza en atributos, como código de respuesta y URL de solicitud. Aquí tienes un ejemplo de la misma información de registro en un formato analizable:
{
"remote_addr":"95.10.51.7",
"time":"1588412603",
"method":"GET",
"path":"/downloads/product_1",
"version":"HTTP/1.1",
"response":"304",
"bytesSent": 0,
"user_agent": "Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.21)"
}
Estandarizar un formato de registros que se pueda utilizar en todas las aplicaciones facilita la incorporación de datos en la plataforma de observabilidad, incluso cuando diferentes equipos desean tener visibilidad de distintos atributos.